Είχα μια ιδέα το τελευταίο διάστημα (η οποία θα μπορούσε να εξελιχθεί και σε διπλωματική στην σχολή μου ίσως…) που θα μπορούσε να είναι και ιδιαίτερα χρήσιμη για όλους εμάς εδώ.
Η ιδέα είναι να δημιουργηθεί ένα αυτόματο σύστημα αναγνώρισης του δρόμου (ή και των δρόμων) που υπάρχουν πάνω σε ένα ρεμπέτικο-λαϊκό τραγούδι. Δηλαδή, να μπορείς να δίνεις ως είσοδο, κάποιο mp3 αρχείο, και αυτό να το κατηγοριοποιεί αυτόματα ανάλογα με τον κυρίαρχο δρόμο (αν υπάρχουν περισσότεροι, θα μπορούσε να δίνει ποσοστό για κάθε δρόμο).
Για να το πετύχω αυτό, θα χρησιμοποιήσω την τεχνική των νευρωνικών δικτύων, είναι μια τεχνική στην οποία με απλά λόγια, εκπαιδεύεις το πρόγραμμά σου δίνοντας παραδείγματα κομματιών και τους δρόμους που τους αντιστοιχούν και αυτό σιγά - σιγά μαθαίνει να αναγνωρίζει. Οπότε όταν λαμβάνει ένα άγνωστο κομμάτι - ηχογράφηση, μπορεί να το κατατάξει σε κάποιον(ους) δρόμο(ους).
Το πρόβλημα το οποίο έχω και χρειάζομαι την βοήθεια όποιου μπορεί να συμβάλλει, είναι ότι για να εκπαιδευτεί αυτό το σύστημα θέλω πάρα - πάρα πολλά παραδείγματα κομματιών. Πάνω από 1000 διαφορετικά κομμάτια στα οποία θα έχει ήδη αναγνωριστεί ο δρόμος τους ώστε να τα δώσω στο σύστημα προς εκμάθηση. Αυτή την πληροφορία, δύσκολα θα μπορέσω να την συγκεντρώσω μόνος μου.
Όμως, πιστεύω όλοι μαζί μπορούμε να το συγκεντρώσουμε και σιγά - σιγά να χτίσουμε μια βάση κομματιών και των δρόμων που αντιστοιχούν σε αυτά ώστε μετά να μπορέσω να φτιάξω αυτή την εφαρμογή.
Υπόσχομαι ότι και η βάση των κομματιών, αλλά και η εφαρμογή όταν θα ολοκληρωθεί, θα είναι διαθέσιμη ανοιχτά, εδώ στο φόρουμ, ώστε να την χρησιμοποιεί το ευρύ κοινό.
Τι κομμάτια θέλουμε:
Ιδανικά χρειαζόμαστε κομμάτια που:
Είναι καθαρά ως προς τον δρόμο που ανήκουν (πχ το “στον Ωρωπό” είναι σχετικά καθαρό Σαμπάχ).
Καλό είναι να μην περιορίζονται από πνευματικά δικαιώματα (αν και δεν είναι απαραίτητη προϋπόθεση).
Υπάρχουν ηχογραφήσεις που μπορούν εύκολα να βρεθούν.
Λίγες τεχνικές πληροφορίες για τους πιο γενναίους…
Ουσιαστικά αυτό που θέλω να πετύχω είναι να ταξινομήσω τα κομμάτια ανάλογα με το φάσμα των συχνοτήτων τους (μετά από μετασχηματισμό Fourier). Αυτό θα το πετύχω με έναν CNN Classifier, δηλαδή ένα τύπου νευρωνικού δικτύου που θα λαμβάνει ως είσοδο μια φωτογραφία του φάσματος της συχνότητας και θα την κατηγοριοποιεί βάσει του δρόμου που ανήκει.
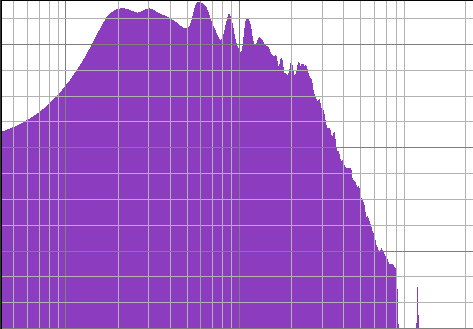
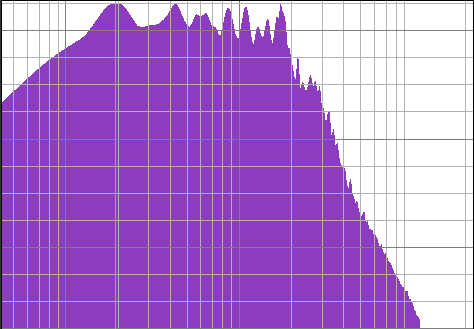
Παρατηρήστε τα παρακάτω διαγράμματα. Αυτά είναι το αποτέλεσμα του μετασχηματισμού Fourier στα κομμάτια “Φέρε μας κάπελα κρασί” και “Σφάλμα ασυγχώρητο”. Και τα δύο είναι αρκετά καθαρά χιτζάζ κομμάτια αν και αρκετά διαφορετικά μεταξύ τους. Αν παρατηρήσετε τα δύο διαγράμματα, με το μάτι (και με λίγο φαντασία) θα δείτε ότι ψιλομοιάζουν.
Μετασχηματισμός Fourier του τραγουδιού “Σφάλμα Ασυγχώρητο”
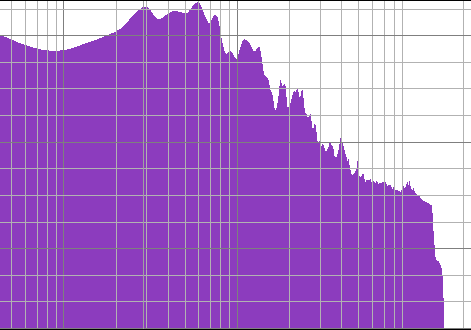
Τώρα όμως δείτε και το διάγραμμα του μετασχηματισμού Fourier πάνω στο κομμάτι “Στον Ωρωπό” που είναι καθαρά σαμπάχ. Αν το δείτε, θα παρατηρήσετε αρκετές διαφορές από τα άλλα δύο (ειδικά περίπου στη μέση του διαγράμματος).
χρήστο λυπάμαι που θα σε στεναχωρήσω, αλλά αυτό που ψάχνεις δεν είναι εφικτό. όπως καλά γνωρίζεις, οι δρόμοι δεν είναι κλίμακες με 7 σταθερούς φθόγγους αλλά τρόποι με κινητούς φθόγγους και έλξεις (χώρια οι συνδυασμοί). ένας μετασχηματισμός fourier ακόμα και αν κατάφερνε να αποδώσει τους σταθερούς φθόγους (και σε μικρότερο βαθμό έλξεις κλπ), δεν θα μας έλεγε τίποτα για την μελωδική συμπεριφορά του δρόμου. και αυτό είναι το πιο σημαντικό στοιχείο που πρέπει να μάθουμε να αναγνωρίζουμε και να διασώσουμε, όχι απλά τα διαστήματα.
επίσης, ακόμα και αν το δοκιμάσει κανείς σαν πρόκληση για προγραμματισμό, προϋποθέτει άριστη γνώση των δρόμων. ενώ το “σφάλμα ασυγχώρητο” είναι όντως χιτζάζ, το “είμαι απόψε στα μεράκια” είναι χουζάμ που καταλήγει σε χιτζασκιάρ (πολύ συνηθισμένος συνδυασμός και συμβαδίζει με την θεωρία). επίσης ο “ωρωπός” είναι όντως ξεκάθαρο σαμπάχ, γιατί στην αρχή το χαρακτηρίζεις “σχετικά καθαρό”;
πέρα απ’όλα αυτά, είναι τεχνικά δύσκολο να βρεθούν και 1000 κομμάτια και χωρίς δικαιώματα και σε καθαρές κόπιες και χωρίς μίξη δρόμων, και μάλιστα να συμφωνήσουμε όλοι στο τί δρόμος είναι το καθένα και πώς λέγεται (εδώ θέλει φατσούλα, αλλά δεν ξέρω αν πρέπει να βάλω γέλιο ή κλάμα). δεν ξέρω αν έχεις σαν πρότυπο/αφορμή τα σχετικά προγράμματα για συγχορδίες, τα οποία μπορεί να λειτουργούν σαν γενικός μπούσουλας σε απλά κομμάτια αλλά σε τροπικές μουσικές έχουν παταγώδη αποτυχία.
επιμένω λοιπόν, ότι σημασία έχει να κατανοήσουμε τους δρόμους βάσει ρεπερτορίου και θεωρίας, και να φτιάχνουμε ταξίμια και τραγούδια αντί για απλουστευτικές εφαρμογές για αρχάριους.
αν δημιουργηθεί η βάση με τα κομμάτια που λες, αυτή όντως θα ήταν χρήσιμη. από κει και πέρα ίσως θα είχε νόημα η εμπλοκή της τεχνητής νοημοσύνης, όπου με γνώση της θεωρίας και δεδομένα από την μελέτη των κομματιών, ίσως να μπορούσε πραγματικά να βρει τον δρόμο ή ακόμα και το μακάμ ενός άγνωστου κομματιού. σου δίνω ιδέες;
υγ: κάτι παρόμοιο είχε προσπαθήσει να κάνει και ένας άλλος φίλος πριν λίγα χρόνια, αλλά δεν νομίζω ότι κατέληξε κάπου.
Συγγνώμη ρε παιδιά. Ξεκάθαρο σαμπάχ είναι, μεν, όχι όμως τυπικό. Αυτή η ύφεση (ξέρετε ποια), μπορεί να είναι σύμφωνη με τη γενική θεωρία περί ουσακοειδών 4χόρδων / 5χόρδων, αλλά στην πράξη δε νομίζω να την έχω ακούσει σε άλλο συγκερασμένο σαμπάχ.
Καλησπέρα Χρήστο. Έχει τύχει να έχω ασχοληθεί με την αναγνώριση μοτίβων και την ταξινόμηση. Βέβαια η δική μου δουλειά ήταν στην αναγνώριση χειρονομιών (αναγνώριση ορισμένων λέξεων της ελληνικής νοηματικής γλώσσας από υπολογιστή με χρήση αισθητήρα Kinect) και όχι ήχου, οπότε δεν έχω γνώμη για τα φυσικά χαρακτηριστικά του ήχου που θα χρησιμοποιηθούν για την αναγνώριση (υποθέτω οι συχνότητες). Ίσως η προσέγγιση σου να δουλέψει δεν ξέρω, ωστόσο έχω να σου κάνω μια άλλη πρόταση. Νομίζω πως στην περίπτωση σου θα ταίριαζε ο αλγόριθμος της δυναμικής χρονικής στρέβλωσης. Γιατί το λέω αυτό; άλλα τραγούδια είναι πιο αργά και άλλα πιο γρήγορα. Ο αλγόριθμος αυτός λύνει το πρόβλημα της διαφορετικής ταχύτητας εκτέλεσης των κομματιών. Επίσης όπως καταλαβαίνω εγώ σε κάθε δρόμο (αν εκτελούνται οι φθόγγοι του με τη σειρά βέβαια, κάτι που προφανώς δεν ισχύει στα τραγούδια) υπάρχει ένας “τύπος” δηλαδή Τόνος, Τόνος, Ημιτόνιο, τόνος, Τριημιτόνιο κλπ άσχετα από ποιον φθόγγο ξεκινάνε. Με τον αλγόριθμο δυναμικής χρονικής στρέβλωσης αρκεί να βρεις έναν γενικό τύπο εξέλιξης του δρόμου (ίσως διαφορετικό για ανιούσα και κατιούσα κλίμακα). Ίσως θα μπορούσες άνετα με τον αλγόριθμο να χρησιμοποιήσεις αυτό που διάβασα (και δεν κατάλαβα) που έγραψε ο Νίκος για πεντάχορδα και τετράχορδα αυξάνοντας την αποτελεσματικότητα. Τέλος το μεγάλο πλεονέκτημα του αλγόριθμου σε σχέση με τα νευρωνικά δίκτυα είναι ο μικρός όγκος δεδομένων εκπαίδευσης, στον οποίο μπορείς όποτε θέλεις να προσθέσεις καινούρια που θα λειτουργήσουν συμπληρωματικά. Δεν χρειάζεται δηλαδή να προσθέσεις 1000 κομμάτια, αλλά ανάλογα με τον αριθμό των δρόμων 4-5 κομμάτια σε έναν δρόμο πιθανά θα οδηγούσαν σε επιτυχία αναγνώρισης άνω του 90%.
Πολυ καλή ιδέα. Δεν νομιζω οτι χρειάζεσαι ουτε καν 100άδες κομμάτια, ουτε απαραίτητα χρειάζεσαι Deep learning για αυτο. Κάνε απλα Peak detection of absolute values of FFT και θα δεις ποιες συχνότητες εμφανίζονται συχνά. Κάθε Δρόμος θα έχει μια μοναδική υπογραφή στις συχνοτητες που πατάει πιο πολύ.
Προτείνω να το κανεις σε Python ωστε να μπορουμε μετα να παιξουμε και απο πανω με Pytorch etc.
Για δεδομενα χρειάζεσαι βασικα να ξερεις ποιες συχνοτητες δημιουργουν την καθε κλίμακα απο καθε τονική, και χρειάζεσαι και καμια 10αρια τραγουδια για να το ρυθμίσεις. Για να μαζεψεις δεδομενα φτιάξε ενα open google sheet με τις κολόνες που χρειάζεσαι (ονομα τραγουδιου, youtube link, δρόμος, τονικότητα ειναι μάλλον αυτα που χρειάζεσαι)
Στα διαγραμματα που εχεις ηδη , πχ το Φερε μας κάπελα, απο τι τονικότητα ειναι ? Μπορουμε να υπολογισουμε ακριβως τις συχνοτητες της κλιμακας και να δουμε αν εχει κορυφες ακριβως εκει ή οχι.
Εδώ έχουμε θεματάκι όμως. Οι πιθανές τονικές είναι άπειρες, κυριολεκτικά, αφού πάντα μπορεί σε μια ηχογράφηση να κούρδισαν λίγο πάνω ή λίγο κάτω, ή ο δίσκος να παίχτηκε λίγο πιο γρήγορα ή λίγο πιο αργά.
Αν πιάσεις ένα καλοκουρδισμένο μπουζούκι ή άλλο όργανο, θα βρειες κομμάτια που μπορείς να παίξεις από πάνω σε μια νορμάλ τονικότητα, άλλα σε άβολη τονικότητα αλλά πάντως εφικτή, και άλλα που δεν τα πιάνεις πουθενά εκτός αν ξανακουρδίσεις αλλού.
Αλλά κι αυτό να μην ήταν, οι συχνότητες της κάθε κλίμακας είναι κάτι που χωράει νερό. Έχεις όργανα συγκερασμένα και ασυγκέραστα, και καμιά φορά ακόμη και φωνές που φαλτσάρουν.
Ε εντάξει και λίγο ξεκουρδιστοι να είναι, θα έχεις θόρυβο 5% στις συχνότητες ? Πόσο να το πάνε πχ το A από 430- 450 ? Πιστεύω πως αν η ανίχνευση κορυφαίων συχνοτήτων αντέχει θόρυβο, θα δουλέψει αρκετά καλά. Θα είναι ενδιαφέρον να το δούμε και αυτό, πόσο φεύγουν οι παλιές ηχογραφήσεις
Νομίζω οσοδήποτε. Δε σκέφτονταν ανέκαθεν όλοι οι μουσικοί με γνώμονα κάποιο εξωτερικό σημείο αναφοράς στο κούρδισμα (440 ή άλλο). Οι Σμυρνιοί με την πιο ορχηστρική και γενικά πιο συστηματοποιημένη παράδοση, μπορεί (ιδίως αν συμμετέχουν πνευστά, σαντούρια ή κανονάκια, ή βέβαια πιάνα). Ένας Καραπιπέρης ή ένας Μπάτης, από πού κι ως πού να πρέπει να πάρει τόνο από κάπου για να κουρδίσει; Κουρδίζει τις χορδές μεταξύ τους και τέλος.
Δεν έχω κάνει συστηματικές παρατηρήσεις του τύπου «εδώ ακούω Ντο# αλλά μάλλον πρέπει να είναι Ρε μισό τόνο ξεκούρδιστο», αλλά μου έχει συμβεί πάρα πολλές φορές να κουρδίζω το όργανο πάνω σε μια ηχογράφηση για να τη βγάλω, και ο τόνος της επόμενης ηχογράφησης να μην είναι πουθενά! Και θυμάμαι και μια παρατήρηση του Σταύρου Κ. σε κάποιο κείμενο για ντουζένια, όπου είχε βρει έναν μπουζουξή (Μάρκο;) κουρδισμένο ενάμιση τόνο πάνω, δηλ. να παίζει Φα με πάτημα Ρε.
[Μάλιστα παλιά, προ ΥΤ, τον καιρό εκείνο που για ν’ ακούσουμε ένα κομμάτι έπρεπε να κάνουμε ορισμένες κινήσεις όχι μόνο με τα δάχτυλα (μερικά κλικ) αλλά να σηκωθούμε, να βρούμε τον δίσκο, να τον βγάλουμε από τη θήκη κλπ., για κάποια κομμάτια που τα είχα σε βινύλιο αξιοποιούσα τη σπάνια δυνατότητα του πικάπ μου να πιάνει όχι μόνο 45 και 33 στροφές και άλλες δύο πιο σπάνιες, αλλά και όλες τις ενδιάμεσες. Έτσι, αντί να κουρδίζω το όργανο πάνω στην ηχογράφηση, κούρδιζα το πικάπ στον τόνο του οργάνου!]
Με τον αλγόριθμο που ανέφερα ξεπερνιέται το πρόβλημα της ταχύτητας εκτέλεσης ενός κομματιού, ενώ δεν είναι ανάγκη να χρησιμοποιούνται οι απόλυτες τιμές των συχνοτήτων, αλλά κάποιος άλλος τύπος. Φαντάζομαι πως μπορεί να βγει ένας τύπος που από το ΛΑ σε ελεύθερη τη μεσαία χορδή (220HZ) και ΛΑ στο 12ο τάστο (440 ΗΖ) θα προκύπτει σωστά το επόμενο ημιτόνιο κ.ο.κ. και στις δυο περιπτώσεις. Επίσης αυτός ο τύπος ακόμα και αν το όργανο έχει κουρδιστεί λανθασμένα πχ ΛΑ με ελεύθερη χορδή (225 ΗΖ) θα δίνει τη συχνότητα που θα έχει για το συγκεκριμένο κούρδισμα το επόμενο ημιτόνιο. Επίσης ακόμα και αν ένα τραγούδι που είναι γραμμένο πχ σε ΡΕ χιτζάζ σε κάποια εκτέλεση είναι σε ΝΤΟ Χιτζάζ μπορεί να ληφθεί μέριμνα στον αλγόριθμο ώστε να το αναγνωρίζει ως Χιτζάζ.
Βέβαια ειλικρινά θα ήθελα να θέσω ένα ερώτημα. Θα είχε πραγματικά οποιαδήποτε χρησιμότητα κάτι τέτοιο; ρωτάω, γιατί όντως είναι αρκετή προγραμματιστική δουλειά και βέβαια φαντάζομαι πως οι ηχογραφήσεις θα πρέπει να καθαρίσουν όσο γίνεται από “θόρυβο”. Δηλαδή θα υπάρξει πολύ χαμαλίκι και σε αυτό το κομμάτι από αυτόν που θα το αναλάβει.
δεν υπάρχει “λάθος” λα, παλιά ήταν 432Hz ή και αλλού. εξάλλου ακόμα και τώρα στις παρέες μεταξύ τους κουρδίζουνε. τουλάχιστον πριν έρθουν τα ψηφιακά κουρδιστήρια, μετά κουφαθήκαμε όλοι…
περικλή, πρέπει να ήσουν από τους πολύ τυχερούς που είχες πικάπ με pitch! τώρα βέβαια το κάνουν αυτό ειδικά προγραμματάκια όπως το amazing slow downer και άλλα. θυμάμαι πριν είκοσι χρόνια που είχα χρυσοπληρώσει ένα κασσετόφωνο της ibanez, κατέβαζε στο μισό την ταχύτητα της κασσέτας και επίσης έβαζες την ηλεκτρική και είχε κάτι άθλια εφέ (fuzz και chorus). το χειρότερο όμως ήταν ότι η ταχύτητα κατέβαινε σχεδόν στο μισό οπότε πέρα από το ότι ήταν μια οκτάβα κάτω φάλτσαρε κιόλας… μετά βγήκαν τα πρώτα ψηφιακά, κάνανε καλή δουλειά αν και με χαμηλή δειγματοληψία.
όλα αυτά μπορεί να φαίνονται εκτός θέματος, όμως νομίζω τονίζουν αυτό που είπα και στην αρχή. θέλουμε τεχνολογικά βοηθήματα, αλλά να υποστηρίζουν και όχι να υποκαθιστούν εμάς τους ανθρώπους.
Φίλε νομίζω η προσέγγιση σου με μετασχηματισμό φουριέ ολόκληρης της ηχογράφησης είναι λίγο περίεργη και, αν μου επιτρέπετε την αγγλικούρα, brute force. Θα ήταν πιο λογικό να ξεκινήσεις με μετατροπή audio σε midi, και μετά να τρέξεις κάποια αναγνώριση δρόμων (σχετική έρευνα νομίζω γίνεται στο γαλλικό ircam για τους τρόπους του γρηγοριανού μέλους, της τζαζ κλπ). Αλλιώς η αναγνώριση κοιτάζει ένα σωρό άσχετα πράγματα όπως ρυθμό, ηχοχρώματα, ποιότητα ηχογράφησης, θόρυβο κλπ που θα επηρεάσουν το αποτέλεσμα του φουριέ.
Καλησπέρα σε όλους! Κατ’ αρχάς, ευχαριστώ για όλο το feedback σας, τις ιδέες σας και το ενδιαφέρον σας.
Όταν πολλοί άνθρωποι καταθέτουν ιδέες και προτάσεις, είναι πολύ πιθανό κάτι να πετύχει.
Θα προσπαθήσω να απαντήσω στα κυριότερα σημεία σε κάθε έναν σας ξεχωριστά…
Σίγουρα, χρειάζεται άτομα με πολύ καλή γνώση των δρόμων για να δημιουργηθεί η το κατάλληλο αρχικό σύνολο δεδομένων (dataset). Γι’ αυτό και απευθύνθηκα από την πρώτη στιγμή στην κοινότητά μας, γιατί γνωρίζω ότι συλλογικά θα είναι πολύ πιο εύκολο να δημιουργηθεί αυτό. Επιπλέον, αυτό το σύνολο δεδομένων θα είναι πολύ χρήσιμο από μόνο του για όλους ασχολούνται με την μουσική που αγαπάμε.
Ναι, είναι γεγονός, αυτό είναι δύσκολο. Τις τελευταίες ημέρες έψαξα λίγο παραπάνω το θέμα και είδα ότι με την τεχνική του deep learning (τεχνητή νοημοσύνη), μπορείς με κατάλληλες προσαρμογές να αναλύσεις και κομμάτια που έχουν πολλαπλούς δρόμους. Δηλαδή, να δώσεις ΄πολλαπλές ετικέτες σε κάθε κομμάτι στο αρχικό σύνολο δεδομένων. Δηλαδή πχ: το “είμαι απόψε στα μεράκια”, στην βάση μας θα μπορούσε να κατηγοριοποιηθεί ως χουζάμ και χιτζασκιάρ. Οπότε η προϋπόθεση το να μην έχουν τα κομμάτια μίξη δρόμων, δεν είναι τόσο σημαντική τελικά. Επιπλέον, όπως είπα και στην αρχική μου ανάρτηση, δεν είναι απαραίτητο να μην υπάγονται σε πνευματικά δικαιώματα τα κομμάτια… Είναι απλά το ιδανικό.
Είναι γεγονός, ότι οι δρόμοι - μακάμ, είναι πολύ πιο περίπλοκοι από τις κλίμακες της δυτικής μουσικής. Θα μπορούσε λοιπόν, να εκπαιδεύσουμε το σύστημα να αναγνωρίζει πεντάχορδα - τετράχορδα αντί για ολόκληρους δρόμους, όπως πολύ ωραία προτείνει ο @perastikos. Βέβαια, θα πρέπει να προσαρμόσουμε έτσι και το αρχικό σύνολο δεδομένων.
Γι’ αυτό θέλω να χρησιμοποιήσω την τεχνική του deep learning. Ουσιαστικά με την τεχνική αυτή, μπορούμε να γενικεύσουμε την αναγνώριση σε όλες τις τονικότητες, γιατί στην πραγματικότητα, κοιτάει το “σχήμα” - “μορφή” του μετασχηματισμού Fourier και όχι τις απόλυτες συχνότητες. Δηλαδή, δεν το νοιάζουν τόσο τα absolute values, αλλά τα διαστήματα, αλλά και οι έλξεις (καθώς οι συχνότητες που στέκεται η μελωδία πιο πολύ, έχουν μεγαλύτερη τιμή, αν δεν κάνω λάθος).
Γι’ αυτό που εξηγώ παραπάνω, προτιμώ το deep learning από το απλό peak detection.
Το πρόβλημα της ταχύτητας εκτέλεσης στο deep learning, επιλύεται με τεχνικές data augmentation (ουσιαστικά, στο training set, προσθέτεις διαφορετικές εκδοχές του ίδιου κομματιού σε διαφορετικές ταχύτητες αλλά και διαφορετικές τονικότητες - μετά από δική σου προεπεξεργασία). Αλλά προφανώς είμαι ανοικτός να δοκιμάσουμε και άλλες τεχνικές
Το καλό της τεχνικής του deep learning, είναι ότι αν έχεις ικανό αριθμό παραδειγμάτων, το σύστημα μπορεί να γενικεύσει αυτά τα παραδείγματα ανεξαρτήτως ηχοχρώματος, ποιότητας ηχογράφησης, θόρυβο κτλ. Βέβαια, μπορούν να γίνουν πολλά πράγματα στην προεπεξεργασία του dataset, όπως απομόνωση συγκεκριμένων συχνοτήτων, αφαίρεση θορύβου κτλ που θα αυξήσουν ίσως την ακρίβεια του αποτελέσματος και που προγραμματιστικά θα μπορούσαν να γίνουν σχετικά εύκολα.
Αν έχεις κάποια πηγή για την έρευνα αυτή θα ήταν αρκετά ενδιαφέρον! Όμως φαντάζομαι ότι θα είναι πιο δύσκολο μετά να αναλύσεις τα εξαγώμενα midi, γιατί παρ’ ότι θα έχεις πιο καθαρή είσοδο, τελικά θα πρέπει να μπλέξεις με άλλου τύπου τεχνικές όπως Recursive Neural Networks ώστε να αναγνωρίσεις τις δομές που υπάρχουν σε αυτά. Αλλά προφανώς είμαι ανοικτός και σε αυτό αν και δεν ξέρω πόσο αξιόπιστα θα μπορούσε να γίνει η μετατροπή σε midi.
Η χρησιμότητά του θα είναι πιστεύω μεγάλη για όσους μαθαίνουν κάποια κομμάτια, και για όσους θέλουν να ερευνήσουν το ρεπερτόριο του ρεμπέτικου σε μεγάλη κλίμακα. Ας πούμε αν μπορούμε να αναλύσουμε πολλά κομμάτια αυτόματα, μπορούμε έτσι να εξάγουμε συμπεράσματα για την δισκογραφία και τα κομμάτια μαζικά, όπως πόσα χιτζάζ και πόσα ουσάκ κομμάτια υπάρχουν, ποιοί είναι οι πιο συχνοί συνδυασμοί δρόμων, ποιοι οι πιο σπάνιοι. Και άλλα που δεν μπορώ να φανταστώ αυτή τη στιγμή. Το χαμαλίκι είναι κυρίως στην κατηγοριοποίηση του αρχικού dataset. Τα υπόλοιπα πιστεύω θα είναι πιο εύκολα.
@liga_rosa, @garlicbeets αυτό που πρότεινα είναι καθαρά τεχνολογικό βοήθημα. Αν τελικά δουλέψει, δεν πρόκειται να υποκαταστήσει τον άνθρωπο. Απλά θα του δίνει έναν μπούσουλα για το τί υπάρχει μέσα σε ένα κομμάτι. Επιπλέον, θα μπορεί να πετύχει πράγματα σε μαζικό επίπεδο, όπως ανέφερα παραπάνω, που δεν θα μπορούσε να κάνει ένας άνθρωπος μόνος του.
Γενικά…
Γενικά, είμαι ανοικτός σε όλες τις τεχνικές που αναφέρατε εδώ… Πραγματικά δεν περίμενα τέτοια ανταπόκριση και χαίρομαι πολύ που στο φόρουμ μας μπορεί να γίνει και μια τέτοια συζήτηση. Ειλικρινά, με ενδιαφέρει πολύ να δούμε πώς αυτό μπορεί να προχωρήσει…
Χρήστο κάποια στιγμή είχα σκεφτεί να κάνω κάτι αντίστοιχο, αλλά λόγω χρόνου το παράτησα εν τη γενέσει…
Δες τα link παρακάτω, θα σου δώσουν έναν μπούσουλα πως να προσεγγίσεις το όλο project: http://coding-geek.com/how-shazam-works/ https://www.lunaverus.com/cnn
Νομίζω ότι η καλύτερη προσέγγιση είναι αυτή.
Προς το παρόν δεν έχω ξεκινήσει κάτι καθώς λόγω φόρτου εργασίας δεν είναι εύκολο να το ξεκινήσω. Όμως έχω ερευνήσει το θέμα λίγο παραπάνω.
Είναι γεγονός ότι τα δεδομένα που υπάρχουν είναι λίγα. Το θέμα είναι ότι δεν θα γίνει το training πάνω σε ολόκληρα κομμάτια, αλλά σε σύντομες φράσεις αυτών (οπότε αν σπάσεις ένα κομμάτι σε πολλά αποσπάσματα, τότε έχεις μεγαλύτερη ποσότητα δεδομένων. Επίσης, με κάποιες τεχνικές (data augmentation), όπως επιβράδυνση, αλλαγή pitch κτλ μπορείς να βάλεις το ίδιο κομμάτι πολλές φορές στο σύνολο δεδομένων σου.